


Sex Toy or Normal Toy? Build Image Recognition Program in 20 Minutes


TL;DR:
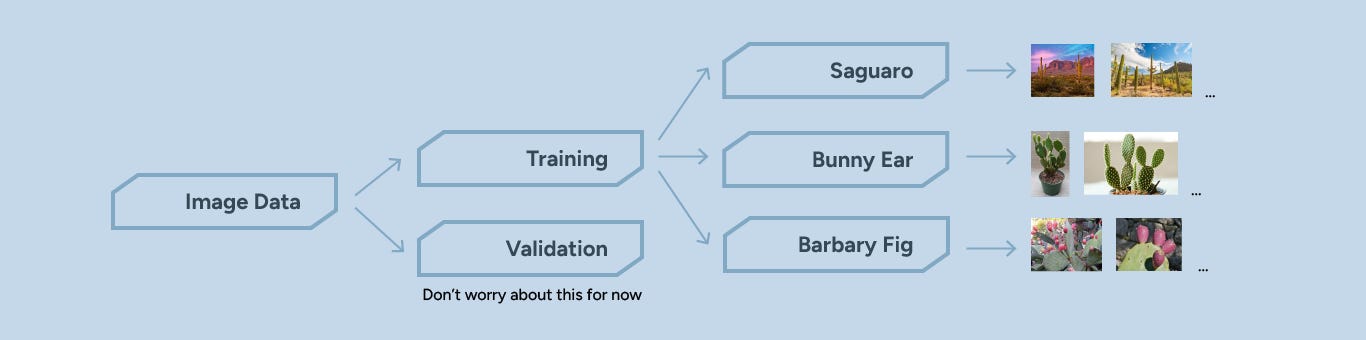
Step 1: Download images and label them
Say you are training the model to identify cactus species, you’d download different images of cactus at different angles, under different lights, etc.
Step 2: Get a off the shelf model with preset weights such as ResNet
Model is a computer program that takes image data, and weights (a number) as inputs, and creates outputs to identify the image or the object in the image.
Step 3: Remove head (last layer) of the model and add our own feature as output
If a model has 50 layers, we’d extract output features from the previous layer, and use it as an input for the last layer, then use our own feature (e.g. number of cactus species) as outputs.
Step 4: Choose a method to fit model mostly likely Stochastic Gradient Descent (SGD)
Fitting the model means base on loss adjust weights to make prediction more accurate. No need to understand SGD deeply to train the first model.
Step 5: Train data, track loss, adjust epochs, adjust learning rate
Loss is a measure of performance, 1 is high and 0.1 is low. You can still do a lot with 0.3.
Learning rate is typically between 0.1 to 0.001, the rule of thumb is start high and go low.
Epoch is the number of cycles you train the model. Too low, you might miss opportunities for optimum weight, too high you might overfit, meaning weights are optimized to recognize training data instead of recognizing generalizable features outside of training data.
Step 6: Get some images that are different from your training set and test the model
People will tell you that you must split data 80/20 to train and validate. It’s totally valid, but it’s also valid to get a couple of images and run them through the model for predictions just for fun.
Tired of reading? Just download this Jupyter notebook and run the code, then try to make modifications so it works for your image classification.

Create your own personal journey into machine learning
You are an artist, a builder or a thinker, and not an academic that obsesses and nitpicks details when it’s not necessary. The purpose of this article is to create the shortest path to train a model to make useful predictions. Don’t know what activation function or dot product is? Even better. However, you need to have minimum knowledge of coding, and have Anaconda installed.
20 Minutes Countdown, Step by Step
Follow along by downloading this code repository.
Select Hardware: Use whatever works for you
Download PyTorch. When you go to their website, it automatically detects your hardware and suggests a package to download.
I have RTX A5000, which is a mildly sophisticated GPU with 8000 cores. An average CUP might have 10 cores. I use GPUs because they can run many programs simultaneously (Parallel Compute), but CPU is a bit limited. If you happened to have Ubuntu 20 and RTX A5000, you can activate my environment.yml
If you don’t have GPU focused machine, you can rent one on AWS or Paper Space.
Gathering Data: Bigger is not always better
You don’t need as much data as you think. In this example, I only used 82 different images for training. However, more data could lead to better performance. As you can guess from the title of this article, we have two labels, normal_toy and sex_toy. You can train for as many labels as you want.
If you’re using your own images, make sure to assign image_dir with the name to your folder. For example, if you want to train for different cactus species, this is what it might look like:

Transform Images: Unlike our eyes, model only sees numbers
We need to crop the image, add some randomness, turn it into a tensor - nested arrays that contain image information, and increase contrast of the image. Cropping it to 224 square is just historical reasons. It can be any size. We then call DataLoader, it makes the image data array more usable with some nice methods.
Then we make sure all the data is loaded. The number should be the same as the number of images.

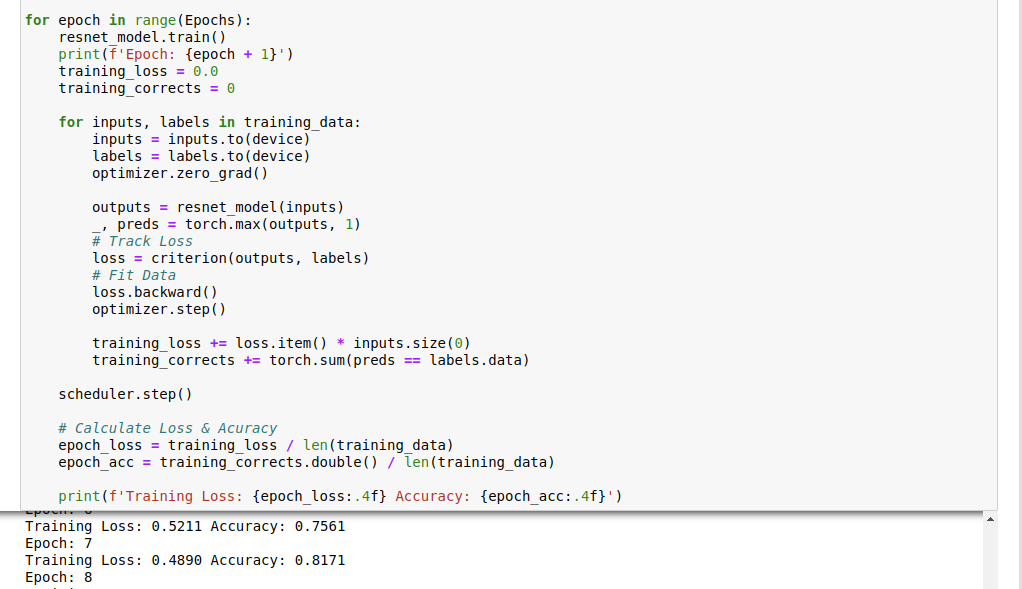
Training Time: Sex toy or not
We’re using a model called ResNet50. Instead of training it from scratch, we load pre-trained weights from the library. The creator already trained the model against vast amounts of images, and set weights to extract meaningful details, it’ll probably be better than any model we’ll ever train from scratch.

In order to make it work for us, we need to remove the last layer. Model.fc is our last layer, we extract input features from previous layers, and use it as an input. Then we use our own features, sex_toy or normal_toy, as outputs.

The performance of the model is determined by loss, a portion of the data that was misidentified. Training Loss reflects data in our training set that was misidentified.

We then fit the data with Stochastic Gradient Descent. When you’re training your own images, you need to play around with the lr parameter, also known as learning rate. Typically, the learning rate is set between 0.1 and 0.001. The approach is usually to set it high and go lower to see which one can minimize loss.

Epoch is how many times we want our model to train the data. There is no exact formula to set the number of epochs. Too little, we miss opportunities, too large, we overfit. If your training loss is low, but when your model keeps misidentifying images outside of the training set, then it’s probably a sign of overfitting.
Party Time: Let’s see how we did
Let’s just have some fun and identify photos outside of the training set. Here are photos I found on Google. Pretty accurate…


Then I decided to produce my own photo. This is my girlfriend holding two different sex toys. Let’s see the performance… of the machine learning model of course.


I’m starting to wonder what specific feature the model recognizes. Maybe the combination of a hand and a long object? Let’s try something different…


Okay, it’s not what I thought, LMAO.
Parting Thought: Track Validation Loss
Typically, most people separate their data into 80/20. 80% of the image used for training, and 20% for validation - see how a model performs. During validation, the model is set to validation mode, and SDG is always turned off.
If you find this article interesting, please consider subscribing.
I also built 💩 for startups: https://tripled.studio